Training a neural network for fun and profit
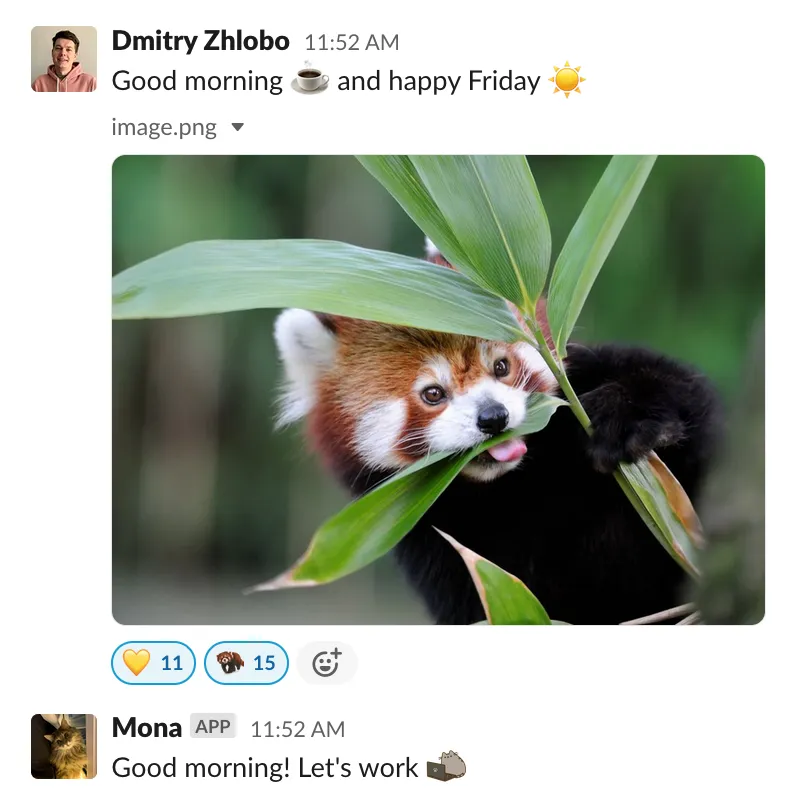
At datarockets, we have a small tradition of greeting teammates with a Happy Friday post in the slack channel with a picture of a cute red panda – our company brand animal.
During a 1-month gap between projects, our developers wanted to try something we have never done before with the potential of applying this knowledge to clients’ projects in the future. Our choice fell on neural networks.
Putting these two together, we came up with the idea of our fun educational project – build and train a neural network to generate unique images of red pandas, and let our custom slack bot Mona (who is an e-cat :)) post a generated panda every Friday with positive wishes to the team.
See the useful links about GANs and neural networks below.
Approach
We started with researching the technical aspects of neural networking, specifically different network architecture types and technologies we could use. This resulted in the following set of technologies: Python as a language and TensorFlow as a machine learning framework. A generative adversarial network (GAN) based on convolutional layers was chosen as a network architecture type.
A whirlwind tour of neural networks
Basically, GAN consists of two neural networks competing with each other – a generator and a discriminator. The generator generates images that are mixed into the training dataset and passed to the discriminator. Discriminator decides whether the images are real or fake, i.e., whether they are from a training dataset or were generated. During that process, the generator corrects its weights based on whether it successfully fooled a discriminator into deciding that generated image was real. And discriminator, in turn, corrects its weights based on whether it correctly distinguished the real image from the generated one. So both networks learn by competing with each other.
Collecting the datasets of red pandas and cats
The path in the technological aspect was cleared out, but to move forward with generating red panda images, we needed a dataset of red panda images to train the network on. We searched on ready datasets of red pandas but did not find a suitable one. However, we did find a data science platform with massive resources of machine learning datasets – Kaggle, which also provides cloud computing power to train the models faster. So at that point, we defined two parallel tasks:
- slowly but surely collect our dataset of red panda images,
- build and adjust a network using another similar dataset – a dataset of >5000 cat face images we found on Kaggle.
First low-resolution images and limitations of GANs
Soon we built our first network attempt, then came a long process of figuring out which parameters and practices lead to the best results. And the best we could squeeze out of that configuration was realistic but low-resolution cat faces (64x64px).

The problem is that GANs are usually limited to small images because higher resolution makes it easier for discriminators to tell the generated images apart from training images, but a stable training process requires the discriminator and generator to find balance.
We clearly needed some solution that would allow us to generate images of higher quality, so we started thinking about alternative network architectures.
Considering SRGAN
First, we considered involving one more network in the flow – SRGAN. SRGAN is an abbreviation for Generative Adversarial Network for image Super-Resolution. The name pretty much tells you its purpose – it translates lower-resolution images to higher-resolution images. The idea was that our model, at that point, would generate 64×64 resolution images, and then SRGAN would upscale them.
Applying Progressive Growing GAN

But a more appealing approach was Progressive Growing GAN – an extension to the GAN training process that involves incrementally increasing the number of layers of the network and, accordingly, the size of input/output images during training. Starting from, for example, 4×4 images and one block of convolutional layers on both discriminator and generator, ending with 256×256 images and seven blocks of convolutional layers. This allows the models first to learn the large-scale structure of the image and then shift attention to increasingly finer scale detail instead of having to learn all scales simultaneously. In the picture, you can see samples of images generated on each stage of training – 8×8, 16×16, 32×32, 64×64, 128×128, and 256×256.
The important thing here was to find the optimal training schedule – from what resolution to start and accordingly a number of stages and training steps for each stage, so none of them get overtrained. Our approach to measuring network performance needed to be improved to do this faster and more precisely.
Results
Our model still has much more potential to realize as we didn’t have much time to adjust it. However, the intermediate results are great, and we are happy to present them. Here are a couple of “good boys”:


And here are a couple of “bad boys”:


As for the second task – collecting the dataset, by the time we had to switch to a new commercial project, we had >500 pictures of red pandas. This number is still too small to train the network.
As said, there is a lot to improve in our project. Maybe one day, some datarockers will pick this project up and continue it. And after expanding our tiny red panda dataset and adjusting the training process on it, we will bring the red panda generator to life.
Useful links
Here you will find the most useful links and articles about GANs and neural networks we explored while implementing this project:
- How to Train a GAN? Tips and tricks to make GANs work (highly recommended)
- How to Identify and Diagnose GAN Failure Modes (highly recommended)
- Convolutional Layers vs Fully Connected Layers
- How to Avoid Overfitting in Deep Learning Neural Networks
- A Gentle Introduction to the Progressive Growing GAN


